Data Variety
Data variety refers to the types of data involved. While you may think of data as just being entries in a spreadsheet, it can come in many different forms. Transactions captured from PoS systems, events generated from sensors, and even pictures can generate valuable insights that businesses can use to make decisions. Ultimately, data falls into three categories: structured, semi-structured, and unstructured.
Structured Data
Structured data can be defined as tabular data that is made up of rows and columns. Data in an Excel spreadsheet or a CSV file is known to be structured, as is data in a relational database such as SQL Server, Oracle, or MySQL. Structured data fits a well-defined schema, which means that every row in a table will have the same number of columns even if one or more of those columns do not have any values in the row. The process of every row in a structured dataset having the same number of columns is known as schema integrity. This is what gives users the ability to create relationships between tables in a relational database. More on this later in this chapter and in Chapter 2.
While schema integrity allows relational data to be easily queried and analyzed, it forces data to follow a rigid structure. This rigid structure forces users to consider how volatile their data will be over time. Considerations for how your schema will evolve over time or the differences between source data’s schema and your target solution will force you to develop sophisticated data pipelines to ensure that this volatility does not negatively impact your solution.
Figure 1.5 illustrates an example of structured data. The data in the figure is product information from the publicly available AdventureWorks2019 database.
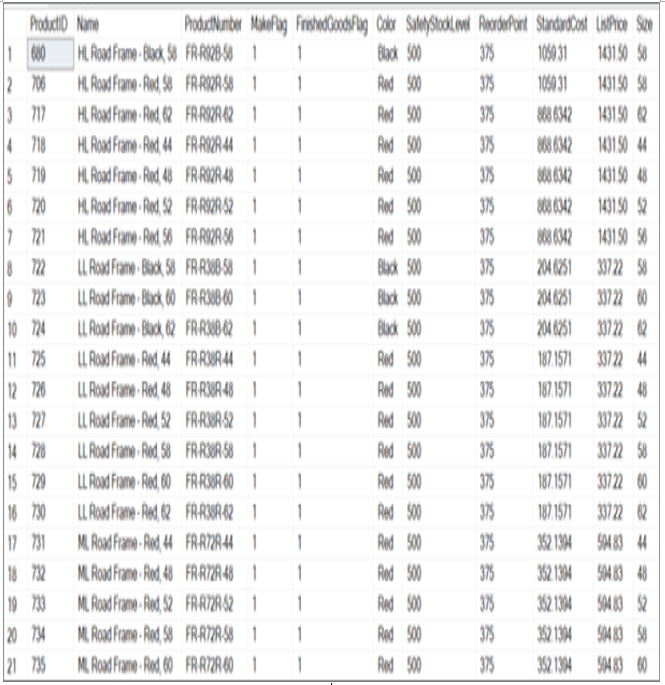
FIGURE 1.5 Structured data