Unstructured Data
Unstructured data is used to describe everything that doesn’t fit in the structured or semi-structured classification. PDFs, images, videos, and emails are just a few examples of unstructured data. While it is true that unstructured data cannot be queried like structured or semi-structured data, deep learning and artificial intelligence (AI) applications can derive valuable insights from them. For example, applications using image classification can be trained to find specific details in images by comparing them to other images.
Storing unstructured data is easier today than it has ever been. As mentioned previously, Azure Blob Storage allows companies and individuals the ability to store exabytes of data in any format. While this exam does not cover the many applications of unstructured data, it is important to note that unstructured data is becoming more and more vital for companies to gain a competitive edge in today’s world.
Data Velocity
The speed at which data is processed is commonly known as data velocity. Requirements for data processing are largely dependent on what business problem or problems we are trying to solve. Raw data such as football player statistics could be stored as raw data until every game for a given week is finished before it is transformed into insightful information. This type of data processing where data is processed in batches is commonly referred to as batch processing. We can also process data from sensors located on equipment that a player is wearing in real time so that we can monitor player performance as the game is happening. This type of data processing is called stream processing.
Batch Processing
Batch processing is the practice of transforming groups, or batches, of data at a time. This process is also known as processing data at rest. Traditional BI platforms relied on batch processing solutions to create meaningful insights out of their data. Concert venues would leverage technologies such as SQL Server to store batch data and SQL Server Integration Services (SSIS) to transform transactional data on a schedule into information that could be stored in their data warehouse for reporting. Many of the same concepts apply today for batch processing, but cloud computing gives us the scalability to process exponentially more data. Distributed computing paradigms such as Hadoop and Spark allow organizations to use compute from multiple commodity servers to process large amounts of data in batch.
Batch processing is typically done in a process of jobs automated by an orchestration service such as Azure Data Factory (ADF). These jobs can be run one by one, in parallel, or a mix of both depending on the requirements for the solution these jobs are a part of. Automated batch jobs can be run after a certain data threshold is reached in a data store but are more often triggered one of two ways:
- On a recurring schedule—an ADF pipeline running every night at midnight, or on a periodic time interval starting at a specified start time.
- Event/trigger-based—an ADF pipeline running after a file is uploaded to a container in Azure Blob Storage.
It is also critical that batch processing includes error handling logic that acts on a failed job. A common architecture pattern that handles batch processing in Azure is illustrated in Figure 1.7.
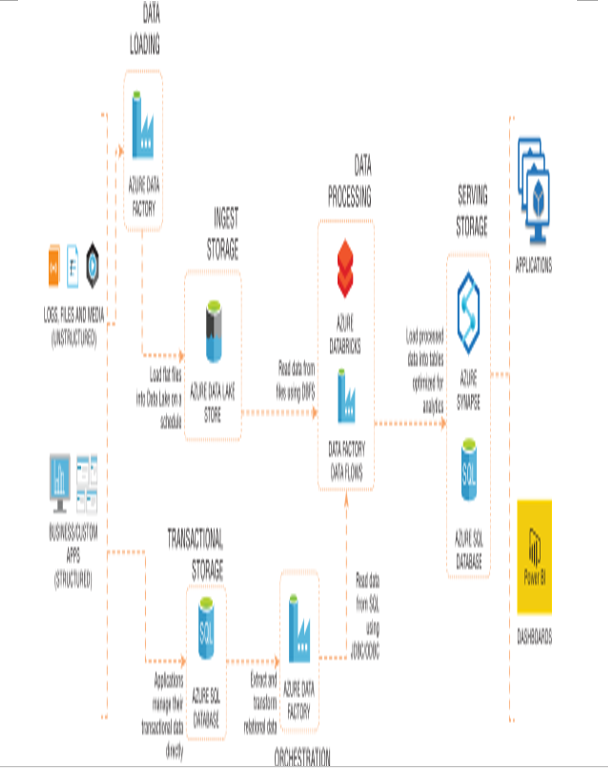
FIGURE 1.7 Common architecture for batch processing in Azure
There is quite a bit going on in the diagram in Figure 1.7, so let’s break it down step-by-step:
- Data is loaded from disparate source systems into Azure. This could vary from raw files being uploaded to a central data repository such as Azure Data Lake Storage Gen2 (ADLS) to data being collected from business applications in an OLTP database such as Azure SQL Database.
- Raw data is then transformed into a state that is analytics and report ready. Here, we can choose between code-first options such as Azure Databricks to have complete control over how data is transformed or GUI-based technologies such as Azure Data Factory Data Flows. Both options can be executed as activities in an ADF pipeline.
- Aggregated data is loaded into an optimized data store ready for reporting. Depending on the workload and the size of data, an MPP data warehouse such as Azure Synapse Analytics dedicated SQL pool can be used to optimally store data that is used for reporting.
- Data that is ready to be reported is then analyzed through client-native applications or a business intelligence tool such as Power BI.