Semi-structured data has some structure to it but no defined schema. This allows data to be written to and read from very quickly since the storage engine does not reorganize the data to meet a rigid format. While the lack of a defined schema naturally eliminates most of the data volatility concerns that come with structured data, it makes analytical queries more complicated as there isn’t a reliable schema to use when creating the query.
The most popular examples of semi-structured datasets are XML and JSON files. JSON specifically is very popular for sharing data via a web API. JSON stores data as objects in arrays, which allows an easy transfer of data. Both XML and JSON formats have somewhat of a structure but are flexible enough that some objects may have more or fewer attributes than others. Because the structure of the data is more fluid than that of a database with a schema, we typically refer to querying semi-structured data as schema-on-read. This means that the query definition creates a sort of quasi-schema for the data to fit in. Figure 1.6 demonstrates how JSON can be used to store data for multiple customers while including different fields for each customer.
There are multiple ways that we can store semi-structured data, varying from NoSQL databases such as Azure Cosmos DB (see Chapter 3) to files in an Azure storage account (see Chapter 4). Relational databases such as SQL Server, Azure SQL Database, and Azure Synapse Analytics can also handle semi-structured data with the native JSON and XML data types. While this creates a convenient way for data practitioners to manage structured and semi-structured data in the same location, it is recommended to limit the amount of semi-structured data you store in a relational database to very little or none.
Semi-structured data can also be stored in other types of NoSQL data stores, such as key-value stores, columnar databases, and graph databases.
In today’s data-driven world, the need to react immediately to unfolding events has never been greater. Picture yourself on the trading floor, where milliseconds can decide millions. Or consider a bustling metropolis where urban sensors constantly monitor traffic, air quality, and energy consumption. Azure Stream Analytics is Microsoft’s answer to the challenges of real-time data ingestion, processing, and analytics.
Azure Stream Analytics is a real-time event data processing service that you can use to har-ness the power of fast-moving streams of data. But what does it really mean for you?
WHY AZURE STREAM ANALYTICS?
Azure Stream Analytics brings the following tools to your toolkit:
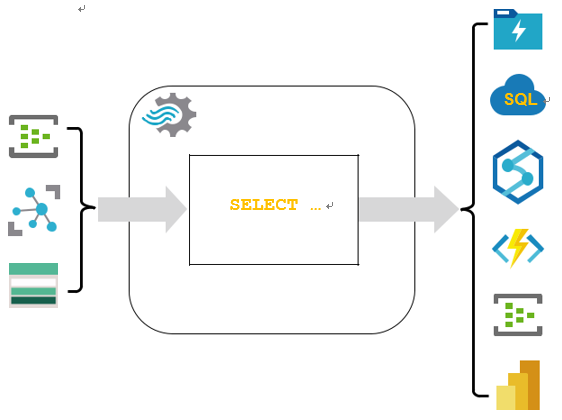
■■ Seamless integration: Azure Stream Analytics beautifully integrates with other Azure services. Whether you’re pulling data from IoT Hub, Event Hub, or Blob Storage, Stream Analytics acts as your cohesive layer, processing and redirecting the data to databases, dashboards, or even other applications, as shown in Figure 4-17.
■■ SQL-based query language: You don’t need to be a programming wizard to harness Azure Stream Analytics. If you’re familiar with SQL, you’re already ahead of the curve. Stream Analytics employs a SQL-like language, allowing you to create transformation queries on your real-time data.
FIGURE 4-17 Azure Stream Analytics
■■ Scalability and reliability: One of the hallmarks of Azure Stream Analytics is its abil-ity to scale. Whether you’re processing a few records or millions every second, Stream Analytics can handle it. More so, its built-in recovery capabilities ensure that no data is lost in the case of failures.
122CHAPTER 4 Describe an analytics workload on Azure
■■ Real-time dashboards: Azure Stream Analytics is not just about processing; it’s also about visualization. With its ability to integrate seamlessly with tools like Power BI, you can access real-time dashboards that update as events unfold.
■■ Time windowing: One of the stand-out features you’ll appreciate is the ease with which you can perform operations over specific time windows—be it tumbling, sliding, or hopping. For instance, you might want to calculate the average temperature from IoT sensors every five minutes; Stream Analytics has got you covered.
Tumbling window in stream processing refers to a fixed-duration, nonoverlapping interval used to segment time-series data. Each piece of data falls into exactly one window, defined by a distinct start and end time, ensuring that data groups are mutu-ally exclusive. For instance, with a 5-minute tumbling window, data from 00:00 to 00:04 would be aggregated in one window, and data from 00:05 to 00:09 in the next, facilitat-ing structured, periodic analysis of streaming data.
Sliding window in stream processing is a type of data analysis technique where the window of time for data aggregation “slides” continuously over the data stream. This means that the window moves forward by a specified slide interval, and it overlaps with previous windows. Each window has a fixed length, but unlike tumbling windows, sliding windows can cover overlapping periods of time, allowing for more frequent analysis and updates. For example, if you have a sliding window of 10 minutes with a slide interval of 5 minutes, a new window starts every 5 minutes, and each window overlaps with the previous one for 5 minutes, providing a more continuous and overlapping view of the data stream.
Hopping window in stream processing is a time-based window that moves forward in fixed increments, known as the hop size. Each window has a specified duration, and the start of the next window is determined by the hop size rather than the end of the previ-ous window. This approach allows for overlaps between windows, where data can be included in multiple consecutive windows if it falls within their time frames. For example, with a window duration of 10 minutes and a hop size of 5 minutes, a new window starts every 5 minutes, and each window overlaps with the next one for a duration determined by the difference between the window size and the hop size.
■■ Anomaly detection: Dive into the built-in machine learning capabilities to detect anomalies in your real-time data streams. Whether you’re monitoring web clickstreams or machinery in a factory, Azure Stream Analytics can alert you to significant deviations in patterns.
As a practical example to truly appreciate the potential of Azure Stream Analytics, consider a smart city initiative. Urban sensors, spread across the city, send real-time data about traf-fic, energy consumption, and more. Through Azure Stream Analytics, this data is ingested in real time, processed to detect any irregularities such as traffic jams or power surges, and then passed on to Power BI dashboards that city officials monitor. The officials can then take imme-diate action, such as rerouting traffic or adjusting power distribution.
Skill 4.2 Describe consideration for real-time data analytics CHAPTER 4123
In summary, Azure Stream Analytics is a tool for those yearning to transform raw, real-time data streams into actionable, meaningful insights. And as you delve deeper into its features and integrations, you’ll realize that its possibilities are vast and ever-evolving.
The process of taking raw data and turning it into useful information is known as data analytics. Companies that invest in sophisticated, well-designed data analytics solutions do so to discover information that helps the overall performance of the organization. Finding new opportunities, identifying weaknesses, and improving customer satisfaction are all results that come from data analytics. This involves building a repeatable solution that collects data from the appropriate source systems, transforms it into dependable information, and serves it in a way that is easy to consume.
One example of an end-to-end data analytics solution is a sports franchise that would like to build a fan engagement solution to improve stadium attendance rates and in-stadium retail sales by retaining more season ticketholders and creating incentive-based programs for different fan groups. The first step to create this solution will be to identify the sources of data that will be most useful to answering questions related to who attends games and what external factors may influence attendance rates. The next step will be to take these disparate sources of data and transform them so that they present a reliable view of the data that can be easily read by consumers who are acting on the data. For example, consumers of the data could be data scientists who develop regression models that predict future stadium attendance or analysts who build reports and dashboards that display in-stadium trends for different fan groups. These actions are then used to create decisions that will enhance ticket sales and operational efficiency during a game.
Data Processing Techniques
The most critical part of a data analytics solution is that the result set is clean, reliable data. Consumers of the data must be able to retrieve the same answer from a question, regardless of how the question is presented to the data model. There cannot be a question of the quality of data being reported on. This is the goal of data processing.
Simply put, data processing is the methodology used to ingest raw data and transform it into one or more informative business models. Data processing solutions will ingest data either in batches or as a stream and can either store the data in its raw form or begin transforming it. Data can undergo several transformations before it is ready to be reported on. Some of the most common transformation activities are as follows:
Filtering out corrupt, duplicated, or unnecessary data
Joining data or appending it to other datasets
Normalizing data to meet a standard nomenclature
Aggregating data to produce summarizations
Updating features to a more useful data type
Data processing pipelines must include activities that are repeatable and flexible enough to handle a variety of scenarios. Tools such as ADF, Azure Databricks, and Azure Functions can be used to build processing pipelines that use parameters to produce desired results. These tools also allow developers to include error handling logic in their processing pipelines to manage how pipelines proceed if processing errors present themselves without bringing the pipeline to a screeching halt.
Cloud-based data processing solutions make it easy to store data after multiple stages of transformations. Storage solutions such as ADLS allow organizations to store massive amounts of data very cheaply in folders designated for raw data that was just ingested, data that has been filtered and normalized, and data that has been summarized and modeled for reporting. This allows data processing solutions to reuse data at any point in time to validate actions taken on the data and produce new analysis from any point in the data’s life cycle.
There are two data processing approaches that can be taken when extracting data from source systems, transforming it, and loading the processed information into a data model. These approaches are extract, transform, and load (ETL) and extract, load, and transform (ELT). Choosing between them depends on the dependency between the transformation and storage engines.
When you dive into Power BI, you’re immersing yourself in a universe of functionalities, each tailored to elevate your data visualization and analytical skills. Here’s a guide to help you navi-gate and harness the essential capabilities of this remarkable tool.
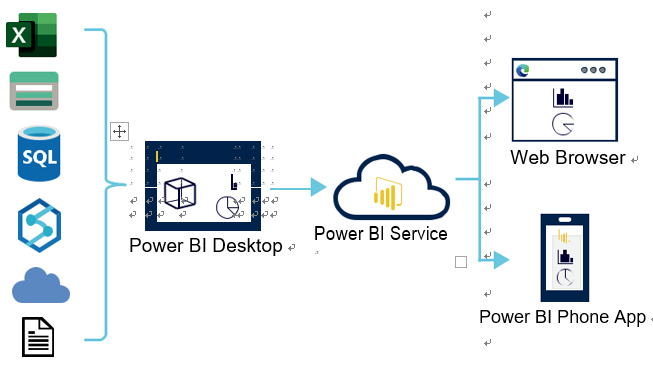
Seamless data integration: At the heart of every great visualization lies the data that drives it. With Power BI you can connect effortlessly to a diverse range of data sources, be it local databases, cloud-based solutions, Excel spreadsheets, or third-party plat-forms, as shown in Figure 4-21. The beauty of it is that once the data is connected, you can consolidate and transform that data, paving the way for rich, meaningful visualizations.
FIGURE 4-21 Power BI data ingestion process
Intuitive drag-and-drop features: You don’t need to be a coding wizard to craft com-pelling visuals in Power BI. With its user-friendly interface, designing everything from simple charts to complex dashboards becomes an intuitive, drag-and-drop affair. Pic-ture yourself effortlessly juxtaposing a line graph next to a pie chart, bringing multiple data stories into a coherent narrative.
Advanced data modeling: Beyond its visualization prowess, Power BI arms you with robust data modeling tools. With features like Data Analysis Expressions (DAX), you can create custom calculations, derive new measures, and model your data in ways that resonate best with your analysis needs.
128CHAPTER 4 Describe an analytics workload on Azure
Interactive reports and dashboards: Static visuals tell only half the story. With Power BI, your visualizations come alive, offering interactive capabilities that encourage exploration. Imagine a sales dashboard where clicking a region dynamically updates all associated charts, revealing granular insights with a mere click.
Collaboration and sharing: Crafting the perfect visualization is one thing; sharing it is another. Power BI streamlines collaboration, meaning you can publish reports, share dashboards, and even embed visuals into apps or websites. Your insights, once confined to your device, can now reach a global audience or targeted stakeholders with ease.
As a practical example, consider you’re managing the sales division for a global enter-prise. With Power BI, you can effortlessly integrate sales data from various regions, model it to account for currency differences, and craft a dynamic dashboard. Now, with a simple click, stakeholders can dive into regional sales, identify top-performing products, and even forecast future trends. As your proficiency with Power BI grows, there’s always more to discover. As you chart your data journey with Power BI, remember that every insight you unearth has the potential to inform, inspire, and innovate.
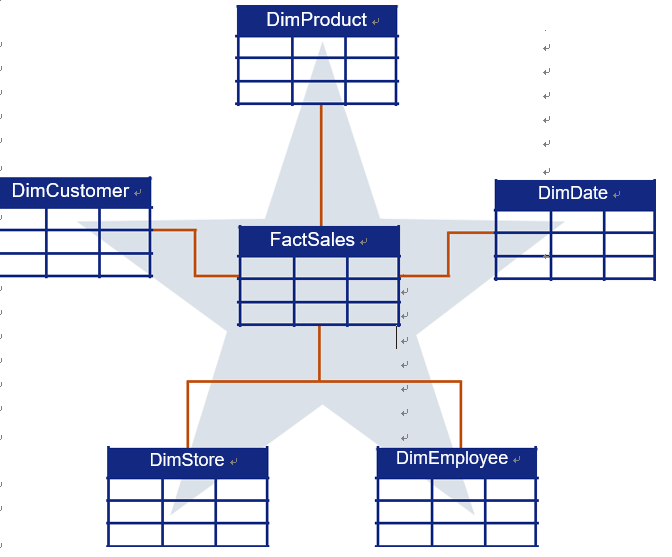
■■ Star schema: One of the most prevalent schema designs in Power BI, the star schema consists of a central fact table surrounded by dimension tables. The fact table houses quantitative data (like sales amounts), while dimension tables contain descriptive attributes (like product names or customer details). This structure, resembling a star as shown in Figure 4-23, ensures streamlined data queries and optimal performance.
FIGURE 4-23 Star schema
Snowflake schema: An evolution of the star schema, the snowflake schema sees dimension tables normalized into additional tables, as shown in Figure 4-24. This schema can be more complex but offers a more granulated approach to data relation-ships, making it apt for intricate datasets.
Skill 4.3 Describe data visualization in Microsoft Power BICHAPTER 4131
FIGURE 4-24 Snowflake schema
DimEmployee
A PRACTICAL SCENARIO
Imagine running an online bookstore. You have tables for orders, customers, books, and authors. Using the star schema, the Orders table sits at the center as your fact table, containing transaction amounts. The other tables serve as dimensions, with the Books table containing a foreign key linking to the Authors table, establishing a many-to-one relationship.
Harnessing the potential of table relationships and choosing the right schema in Power BI isn’t just a technical endeavor; it’s an art form. By understanding and correctly implementing these relationships, you’re crafting a tapestry where data flows seamlessly to offer insights that are both deep and interconnected.
Creating a hierarchy in Power BI is straightforward. In the Fields pane, you can simply drag one field onto another to initiate a hierarchy. From there, you can add or rearrange fields, tailoring the hierarchy to your analytical needs.
A PRACTICAL ILLUSTRATION
Imagine managing a retail chain with stores across multiple countries. You could construct a geographical hierarchy with the following levels:
Continent (e.g., North America)
Country (e.g., United States)
State (e.g., California)
Skill 4.3 Describe data visualization in Microsoft Power BICHAPTER 4133
City (e.g., San Francisco)
Store Location (e.g., Market Street)
With this hierarchy in place, a map visualization in Power BI becomes a dynamic exploration tool. At the highest level, you see sales by continent. As you drill down, you traverse through countries, states, and cities, finally landing on individual store locations. This hierarchical jour-ney offers insights ranging from global sales trends down to the performance of a single store.
In the realm of Power BI, hierarchies are more than just structural tools; they’re gateways to layered insights. By understanding and adeptly utilizing them, you can craft data stories that resonate with depth, clarity, and context.
Measures and Calculated Columns
Data seldom fits perfectly into our analytical narratives. Often, it requires tweaking, transfor-mation, or entirely new computations to reveal the insights we seek. Power BI acknowledges this need with two potent features: measures and calculated columns. These tools, driven by the powerful DAX language, grant you the capability to sculpt and refine your data. Here, we’ll dive deep into these features, elucidating their distinctions and utilities and bringing them to life with hands-on examples.
A measure is a calculation applied to a dataset, usually an aggregation like sum, average, or count, that dynamically updates based on the context in which it’s used. For instance, the same measure can provide the total sales for an entire year, a specific month, or even a single prod-uct, depending on the visualization or filter context. Measures are immensely useful when you want to examine aggregated data. They respond to user interactions, ensuring that as filters or slicers are applied to a report, the measures reflect the appropriate, contextual data.
A calculated column is a custom column added to an existing table in your data model. The values of this column are computed during data load and are based on a DAX formula that uses existing columns. When you need a new column that’s derived from existing data—for computations or classifications—a calculated column is the go-to tool. Unlike measures, these values remain static and are calculated row by row.
Measures are for aggregating and are context-aware, while calculated columns add new, static data to your tables.
As an example, imagine you’re analyzing sales data for a chain of bookstores. You might create a measure named Total Sales using the formula Total Sales = SUM(Transactions[SalesAmount]). This measure can display total sales across all stores but will adjust to show sales for a specific store if you filter by one.
134CHAPTER 4 Describe an analytics workload on Azure
Using the same bookstore data, suppose you want to classify books into price categories: Budget, Mid-Range, and Premium. You can create a calculated column named Price Category with a formula like this:
This adds a new Price Category column to your Books table, classifying each book based on its price.
Harnessing measures and calculated columns in Power BI are akin to being handed a chisel as you sculpt a statue from a block of marble. They allow you to shape, refine, and perfect your data, ensuring your analyses and visualizations are both precise and insightful. To delve deeper into the world of DAX and custom calculations, the official Microsoft documentation provides a treasure trove of knowledge, from foundational concepts to advanced techniques.
Data categorization in Power BI involves assigning a specific type or category to a data column, thereby providing hints to Power BI about the nature of the data. This categorization ensures that Power BI understands and appropriately represents the data, especially when used in visu-als or calculations.
WHY DATA CATEGORIZATION MATTERS
Data categorization in Power BI is pivotal for extracting maximum value from your datasets, impacting everything from visualization choices to data integrity. It enables Power BI to pro-vide tailored visual suggestions, enhances the effectiveness of natural language queries, and serves as a critical tool for data validation. Here’s why categorizing your data correctly matters:
Enhanced visualization interpretation: By understanding the context of your data, Power BI can auto-suggest relevant visuals. Geographical data, for instance, would prompt map-based visualizations, while date fields might suggest time-series charts.
Improved search and Q&A features: Power BI’s Q&A tool, which allows natural language queries, leans on data categorization. When you ask for “sales by city,” the tool knows to reference geographical data due to the categorization of the City column.
Data validation: Categorization can act as a form of data validation. By marking a column as a date, any nondate values become evident, highlighting potential data quality issues.
Skill 4.3 Describe data visualization in Microsoft Power BI CHAPTER 4135
COMMON DATA TYPES IN POWER BI
In Power BI, the clarity and accuracy of your reports hinge on understanding the core data types at your disposal. Each data type serves a specific purpose, shaping how information is stored, analyzed, and presented. The following are common data types:
Text: Generic textual data, from product names to descriptions
Whole number: Numeric data without decimal points, like quantities or counts
Decimal number: Numeric data with decimal precision, suitable for price or rate data
Date/time: Fields that have timestamps, including date, time, or both
For Chapters 1–4, the content should remain relevant throughout the life of this edition. But for this chapter, we will update the content over time. Even after you purchase the book, you’ll be able to access a PDF file online with the most up-to-date version of this chapter.
Why do we need to update this chapter after the publication of this book? For these reasons:
To add more technical content to the book before the next edition is published. This updated PDF chapter will include additional technology content.
To communicate detail about the next version of the exam, to tell you about our publishing plans for that version, and to help you understand what that means to you.
To provide an accurate mapping of the current exam objectives to the existing chapter content. Though exam objectives evolve and products are renamed, most of the content in this book will remain accurate and relevant. The online chapter will cover the content of any new objectives, as well as provide explanatory notes on how the new objectives map to the current text.
After the initial publication of this book, Microsoft Press will provide supplemental updates as digital downloads for minor exam updates. If an exam has major changes or accumulates enough minor changes, we will then announce a new edition. We will do our best to provide any updates to you free of charge before we release a new edition. However, if the updates are significant enough in between editions, we may release the updates as a low-priced stand-alone e-book.
If we do produce a free updated version of this chapter, you can access it on the book’s product page, simply visit MicrosoftPressStore.com/ERDP9002e/downloads to view and download the updated material.
As the digital age progresses, the influx of data has transformed from a steady stream into a roaring torrent. Capturing, analyzing, and acting upon this data in real time is not just a luxury but a necessity for businesses to remain competitive and relevant. Enter Azure Data Explorer, a service uniquely equipped to manage, analyze, and visualize this deluge of information. This section is your comprehensive guide to understanding and harnessing its immense potential.
WHAT IS AZURE DATA EXPLORER?
Azure Data Explorer (ADX) is a fast, fully managed data analytics service for real-time analysis on large volumes of streaming data. It brings together big data and analytics into a unified platform that provides solutions to some of the most complex data exploration challenges.
Here are its key features and benefits:
■■ Rapid ingestion and analysis: One of the hallmarks of Azure Data Explorer is its abil-ity to ingest millions of records per second and simultaneously query across billions of records in mere seconds. Such speed ensures that you’re always working with the most recent data.
■■ Intuitive query language: Kusto Query Language (KQL) is the heart of Azure Data Explorer. If you’ve used SQL, transitioning to KQL will feel familiar. It allows you to write complex ad hoc queries, making data exploration and analysis a breeze.
■■ Scalability: ADX can scale out by distributing data and query load across multiple nodes. This horizontal scaling ensures that as your data grows, your ability to query it remains swift.
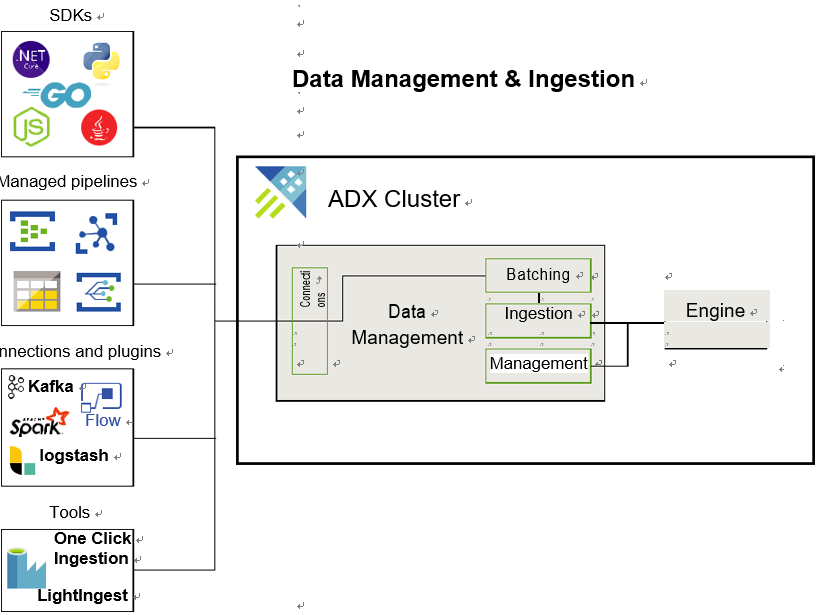
■■ Integration with other Azure services: ADX plays nicely with other Azure services, ensuring that you can integrate it seamlessly into your existing data infrastructure. Whether it’s ingesting data from Event Hubs, IoT Hub, or a myriad of other sources, ADX can handle it. Figure 4-18 shows the end-to-end flow for working in Azure Data Explorer and shows how it integrates with other services.
As a practical use case, imagine you’re overseeing the operations of a global e-commerce platform. Every click, purchase, and user interaction on your platform generates data. With Azure Data Explorer, you can ingest this data in real time. Using KQL, you can then run complex queries to gauge user behavior, analyze purchase patterns, identify potential website hiccups, and more, all in real time. By using this data-driven approach, you can make instantaneous decisions, be they related to marketing strategies or website optimization.
Azure Data Explorer stands as a formidable tool in the data analytics space, empowering users to make the most of their data. Whether you’re a seasoned data analyst or just starting, ADX offers a blend of power and flexibility that can transform the way you view and utilize data.
124 CHAPTER 4 Describe an analytics workload on Azure
The volume of data that the world has generated has exploded in recent years. Zettabytes worth of data is created every year, the variety of which is seemingly endless. Competing in a rapidly changing world requires companies to utilize massive amounts of data that they have only recently been exposed to. What’s more is that with the use of edge devices that allow Internet of Things (IoT) data to seamlessly move between the cloud and local devices, companies can make valuable data-driven decisions in real time.
It is imperative that organizations leverage data when making critical business decisions. But how do they turn raw data into usable information? How do they decide what is valuable and what is noise? With the power of cloud computing and storage costs growing cheaper and cheaper every year, it’s easy for companies to store all the data at their disposal and build creative solutions that combine a multitude of different design patterns. For example, modern data storage and computing techniques allow sports franchises to create more sophisticated training programs by combining traditional statistical information with real-time data captured from sensors that measure features such as speed and agility. E-commerce companies leverage click-stream data to track a user’s activity while on their website, allowing them to build custom experiences for customers to reduce customer churn.
The exponential growth in data and the number of sources organizations can leverage to make decisions have put an increased focus on making the right solution design decisions. Deciding on the most optimal data store for the different types of data involved and the most optimal analytical pattern for processing data can make or break a project before it ever gets started. Ultimately, there are four key questions that need to be answered when making design decisions for a data-driven solution:
What value will the data powering the solution provide?
How large is the volume of data involved?
What is the variety of the data included in the solution?
What is the velocity of the data that will be ingested in the target platform?